Description
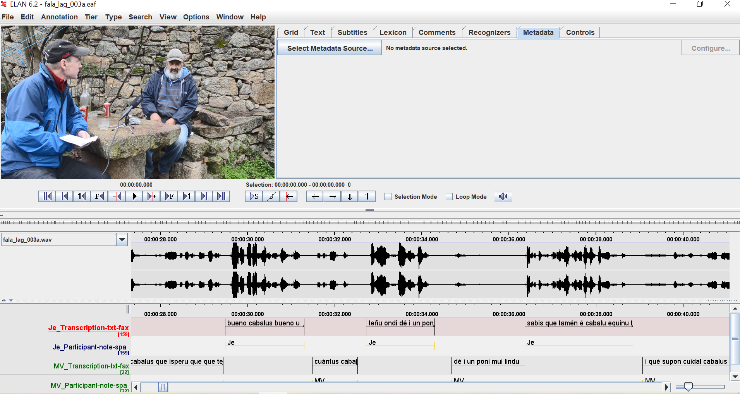
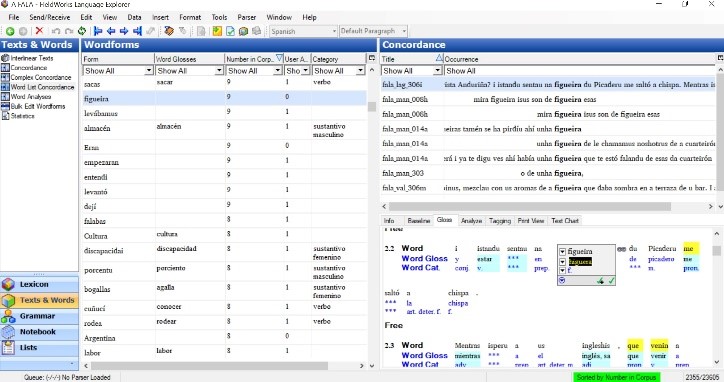
A Fala database contains 337 338 tokens/words documented in 201 texts. It has been compiled from transcribed recordings, which contributed with 190 802 words (57%), and published and unpublished texts written in one of the three varieties of A Fala, which contributed with the remaining 146 536 words (43%). However, due to the copyright issues 7 of the written texts had to be deleted and for that reason this public version has only 194 accessible texts, with 335 000 words.
The objective was to create a database that would reflect both spoken and written aspects of the language, taking into account a variety of factors: equal representation of the three varieties (Lagarteiru, Mañegu and Valverdeñu), participation of both genders (women and men), participation of speakers of different age groups, not only the oldest speakers, and a variety of topics to be covered in the interviews ranging from the traditional ones like the local agriculture to European funds and their local usage. The community of speakers contributed to all stages of the database compilation.
Community participation
Recordings and text production: 172
Including transcriptions and corrections: approx. 210 (5,5% of the population of the three villages)
Technical requirements
You will need version 9 of FLEx to open the database.
FLEx download: https://software.sil.org/fieldworks/download/
The database is password protected. It is available to everyone, but to get the password, please contact: This email address is being protected from spambots. You need JavaScript enabled to view it.
FLEx particularity
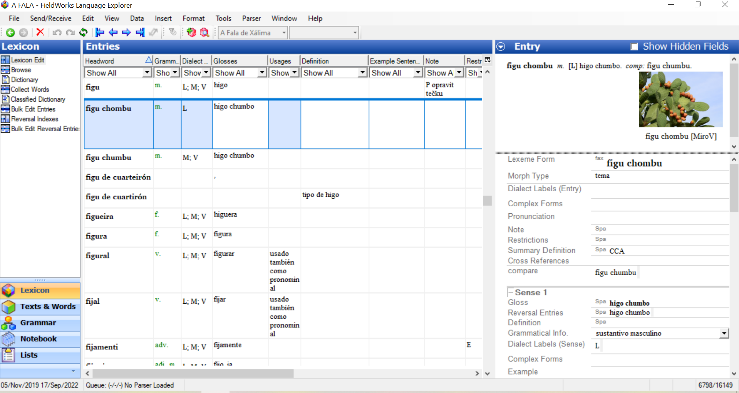
- General note - this line is used for extended comments on usage as the Usages line only offers pre-defined categories.
- Semantic domains – the only semantic domains that have been marked are related to Animals (1.6), Plants (1.5) and Tools (6.7). The categorization is simplified and it will be a matter of future corrections and completion.
- Restrictions – this line reflects the frequency of words. It is also a section to be completed.
no mark = frequent words
A = less frequent words (not marked yet)
B = rare words (not marked yet)
C = very infrequent words – related to the traditional culture, often unused e.g. corsetería
D = very infrequent words – related to Castilian e.g. lasaña, paracetamol
E = adverbs in -menti, they will not be part of the dictionary, but they appear in the database
F = words that are not included in the dictionary, they might be inserted after verification